Databricks sparksql concat is not your SQL Server concat
One of these is not like the other...
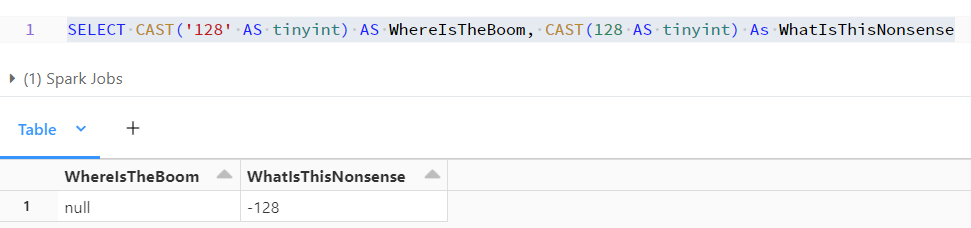
The concat function is super handy in the database world but be aware that the SQL Server one is way better because it solves two problems. It combines everything into a string and it does not require NULL checking. In the before times, one had to down cast to a n/var/char type as well as check for NULL before appending strings via the plus sign.
In Databricks
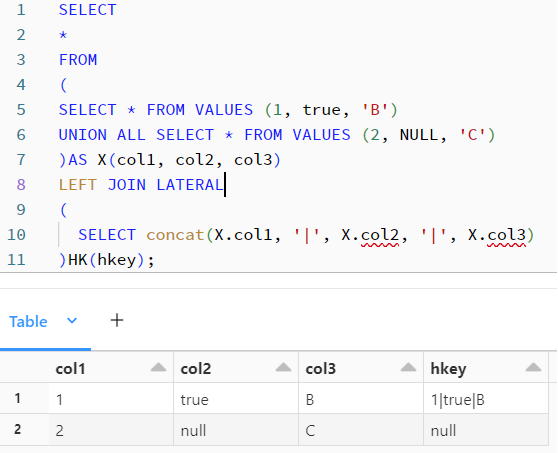
Given the following example query, we generate two rows in a derived table where the col2 value is either true (boolean 1) or NULL. In the LEFT JOIN LATERAL, which is the Databricks CROSS APPLY equivalent, I concat the 3 columns together with a pipe as separator and behold, my decidedly different results from a SQL Server expectation.
SELECT * FROM ( SELECT * FROM VALUES (1, true, 'B') UNION ALL SELECT * FROM VALUES (2, NULL, 'C') )AS X(col1, col2, col3) LEFT JOIN LATERAL ( SELECT concat(X.col1, '|', X.col2, '|', X.col3) )HK(hkey);
What do you do? You get to wrap every nullable column with a coalesce call. Except, coalesce requires the same datatypes (mostly) so a naive implmentation of
SELECT concat(X.col1, '|', coalesce(X.col2, ''), '|', X.col3)will result in the following error
AnalysisException: [DATATYPE_MISMATCH.DATA_DIFF_TYPES] Cannot resolve "coalesce(outer(X.col2), )" due to data type mismatch: Input to `coalesce` should all be the same type, but it's ("BOOLEAN" or "STRING")
Instead, one needs to do something along the lines of
SELECT * FROM ( SELECT * FROM VALUES (1, true, 'B') UNION ALL SELECT * FROM VALUES (2, NULL, 'C') )AS X(col1, col2, col3) LEFT JOIN LATERAL ( SELECT concat(X.col1, '|', coalesce(concat(X.col2, ''),''), '|', X.col3) )HK(hkey);
At least I can automate this pattern with the information_schema.columns