Counting a character in a column
I ran into an issue today that I wanted to write about so that maybe I remember the solution. We ran into a case where the source data in a column had an unprintable character. In this case, it was a line feed character, which is ASCII value 10, and they had 7 instances in this one row. "How did that get in there? Surely that's an edge case and we can just ignore it," and dear reader, I've been around long enough to know that this is likely a systemic situation. To count the number of line feeds in a single row, for a single column, I can just copy the value into NotePad++ or the like, display all characters, and simpely count.
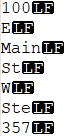
Now, let's count how many line feeds are in a table with 23.5 million rows by hand - Any takers? Exactly. The trick to this solution is that we're going to make use of the REPLACE function to substitute the empty string for all of the values we want to count. We'll then compare the difference in string lengths between the original and the final.
SELECT
*
FROM
(
-- Generate our data
SELECT
CONCAT('100', CHAR(10), 'E', CHAR(10), 'Main', CHAR(10), 'St', CHAR(10), 'W', CHAR(10), 'Ste', CHAR(10), '357', CHAR(10) ) AS InputString
) D0
CROSS APPLY
(
-- What is the difference in string length?
SELECT
LEN(D0.InputString) - LEN(REPLACE(D0.InputString, CHAR(10), '')) AS LFCount
)D1;
This solution is elegant in that you only require one pass through a table to figure out the number. Plus, if you want to do the same computation in other languages that may not have a count function or equivalent available for strings, it likely supports a REPLACE operation.
Is there any other way?
Sure but none of them seem to perform as well.
STRING_SPLIT
Assuming you're on SQL Server 2014?+ the second parater to STRING_SPLIT will be the character to split. Intuitively, I think this might be a more obvious solution. What do we want to do? Count how many times a character exists in a field. If we break the field up into multiple rows and then count how many rows were generated, Bob's your uncle!
SELECT
*
FROM
(
SELECT
CONCAT('100', CHAR(10), 'E', CHAR(10), 'Main', CHAR(10), 'St', CHAR(10), 'W', CHAR(10), 'Ste', CHAR(10), '357', CHAR(10) ) AS InputString
) D0
CROSS APPLY
(
SELECT
COUNT_BIG(SS.value) AS LFCount
FROM
STRING_SPLIT(D0.InputString, CHAR(10)) AS SS
)D1;
What I don't like is the performance. Running those two queries against my original table, it took about 30 seconds to compute the REPLACE's results and 70 seconds for the STRING_SPLIT.
Number table
I'm not going to go find my notes on how to use a number table to perform the same split operation as string_split but I can already tell you, it won't perform as well as string_split and we've already covered that one isn't going to cut it.
I want to count spaces or I'm dealing with unicode data
Fun, but documented, twist --- LEN is not going to count trailing white space. And while I'm a dumb 'murican, unicode length is different so you should probably use DATALENGTH instead, but then divide by 2.
SELECT
*
FROM
(
-- Generate our data
-- We are now using char(32), aka space, as our delimiter
-- and tacking on an extra 100 at the end
-- and we set our type to be nchar
SELECT
CONCAT(CAST('100' AS nchar(3)), CHAR(32), 'E', CHAR(32), 'Main', CHAR(32), 'St', CHAR(32), 'W', CHAR(32), 'Ste', CHAR(32), '357', CHAR(32), space(100) ) AS InputString
) D0
CROSS APPLY
(
SELECT LEN(D0.InputString) AS IncorrectLength
, DATALENGTH(D0.InputString)/2 AS CorrectLength
)D01
CROSS APPLY
(
-- What is the difference in string length?
SELECT
(DATALENGTH(D0.InputString) - DATALENGTH(REPLACE(D0.InputString, CHAR(32), '')))/2 AS SpaceCount
, (LEN(D0.InputString) - LEN(REPLACE(D0.InputString, CHAR(32), ''))) AS SpaceCountWrong
)D1;
Can you think of any other ways to crack this nut?
No comments:
Post a Comment